Hardware Design
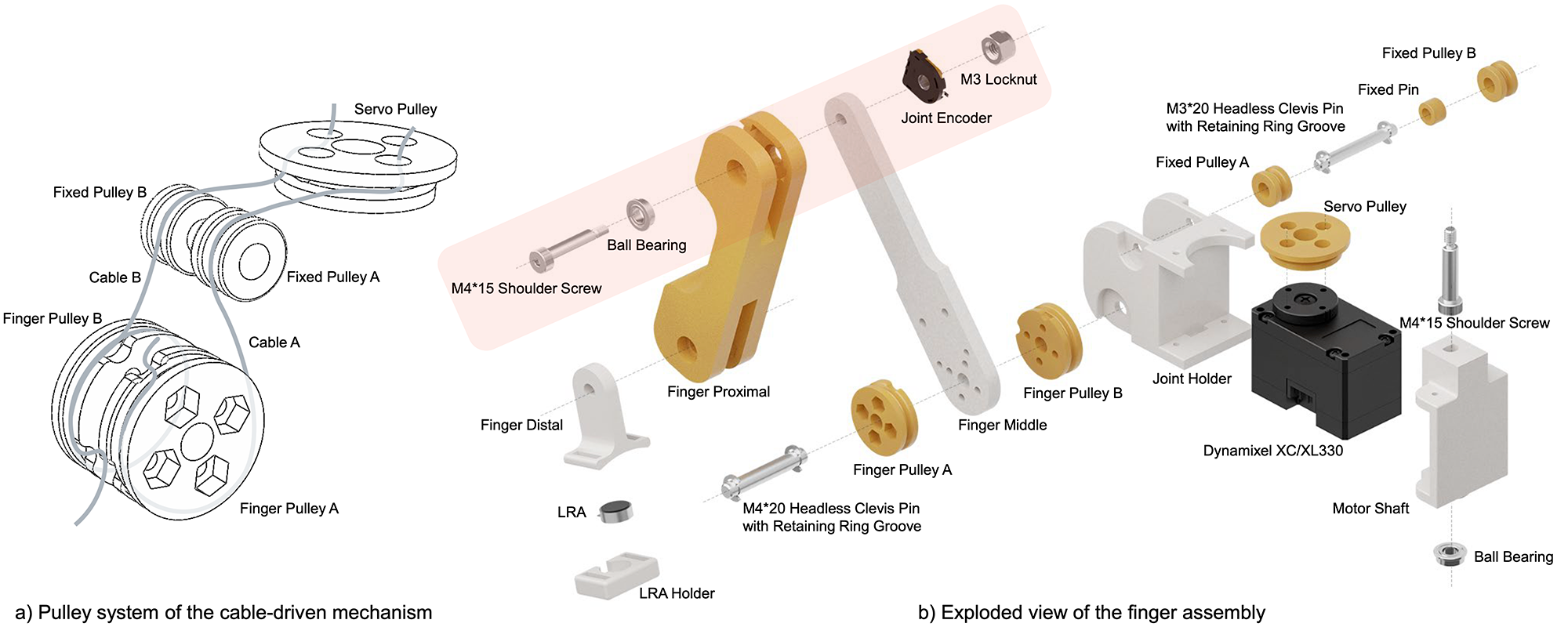
To ensure precise MoCap capabilities and a comfortable wearing experience, DOGlove is designed to closely resemble the anthropomorphic structure of the human hand. It features 21-DoF motion capture and 5-DoF haptic force feedback.
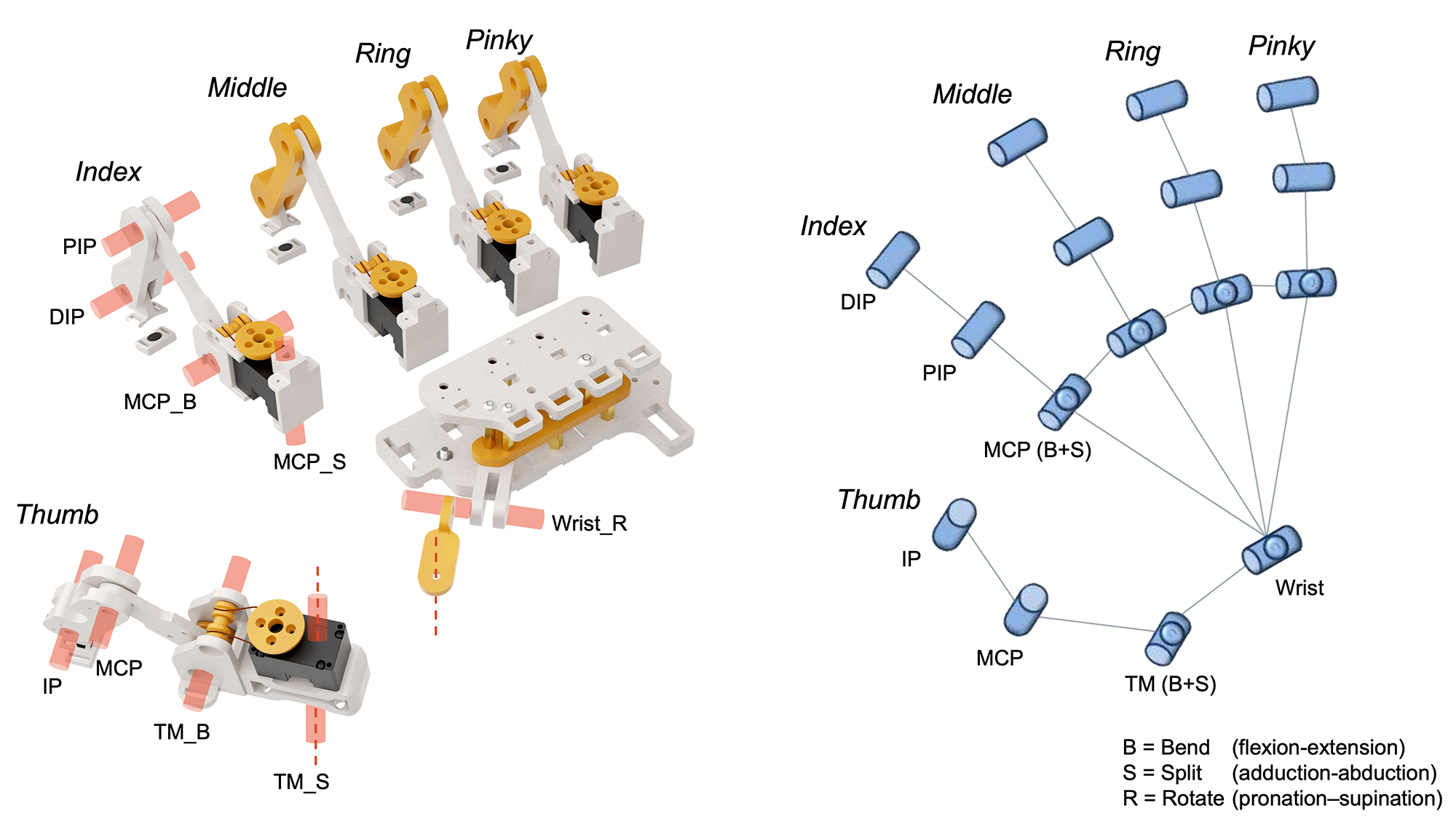
To ensure precise MoCap capabilities and a comfortable wearing experience, DOGlove is designed to closely resemble the anthropomorphic structure of the human hand. It features 21-DoF motion capture and 5-DoF haptic force feedback.
Rotate and place a milk carton.
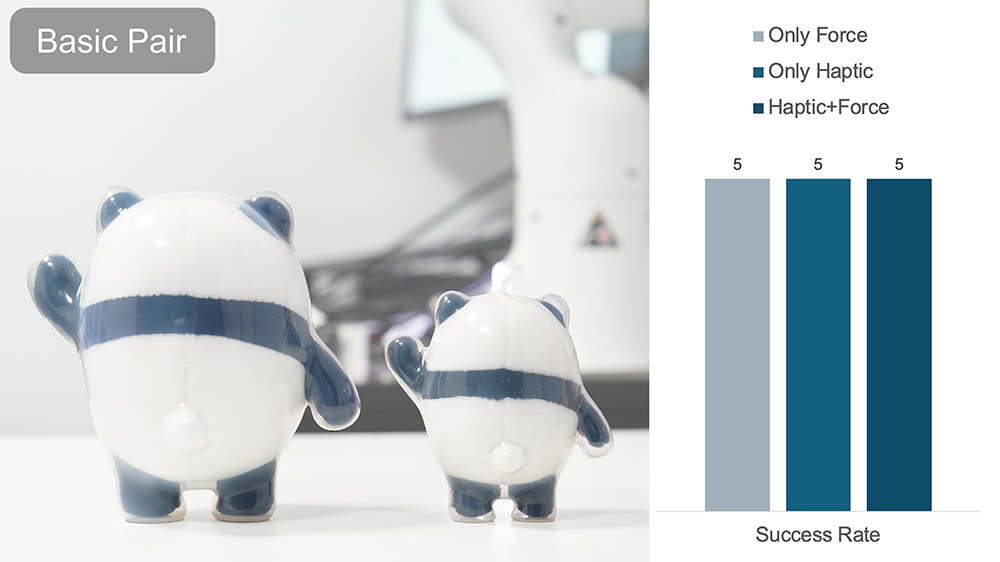
Pick and place a teddy bear.
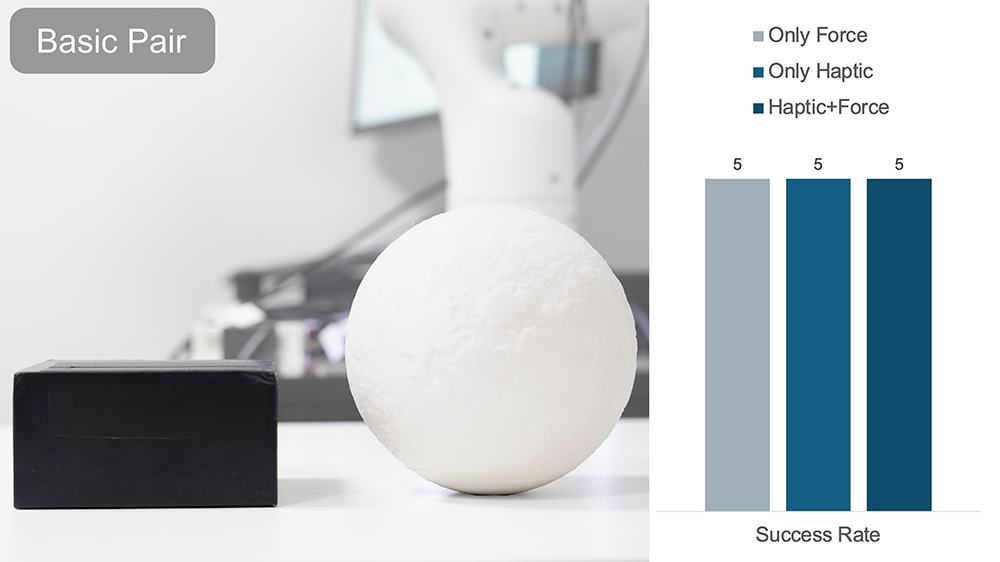
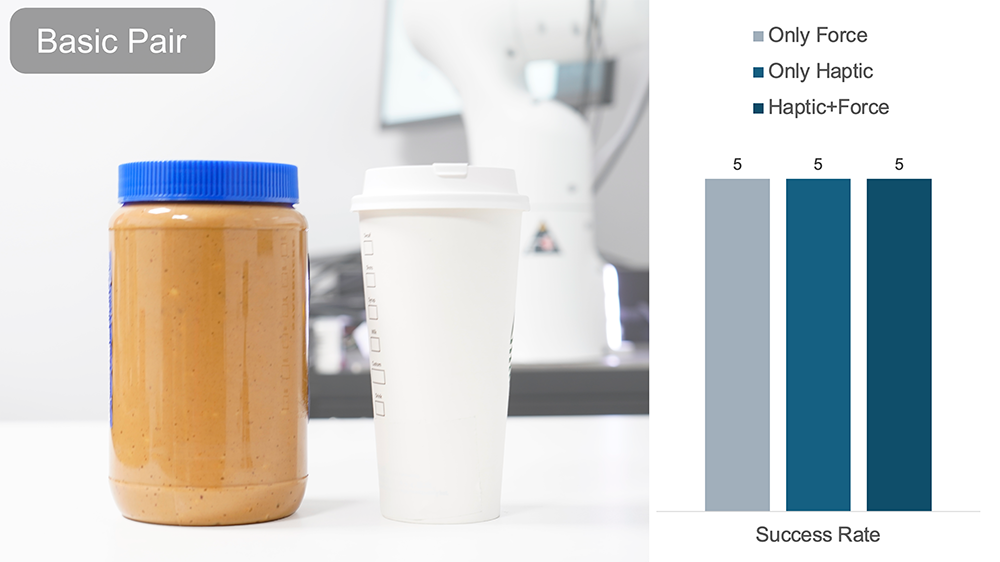
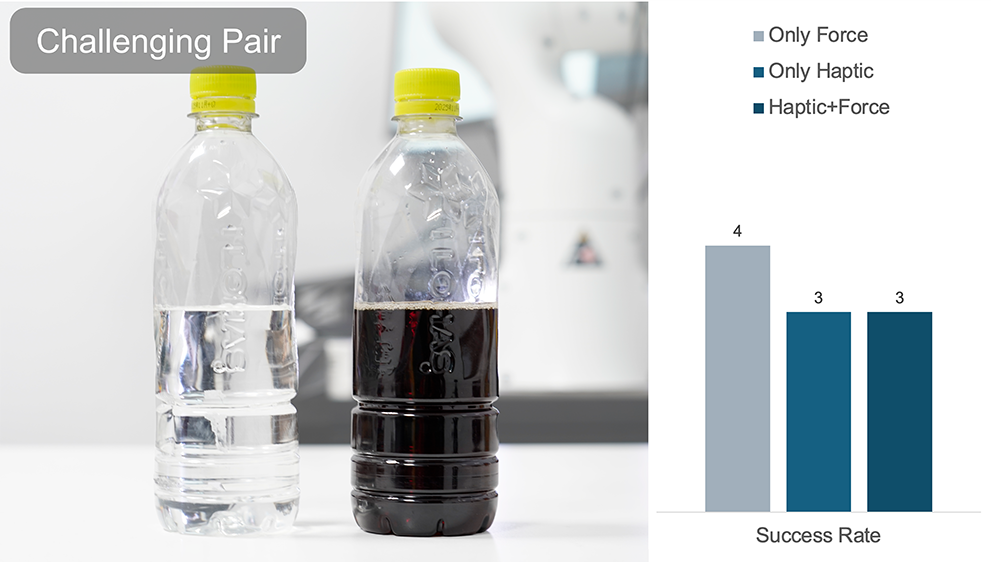
In the above experiment, the human operator must perform a bottle-slipping action using only feedback from DOGlove.
A trial is denoted successful if the bottle slips without falling.
Without visual cues, force feedback significantly improves the success rate.
Adding haptic feedback further enhances overall performance.
To further evaluate control accuracy, when visual input is allowed, the operator must slip the bottle to a precise target distance of 9 cm.
We then measure the deviation between the actual slipping distance and this target.
When visual input is available, force feedback helps operators reduce slipping deviation more effectively.
Haptic force feedback enables operators to achieve a higher success rate and a faster average completion time, as haptic feedback provides contact information, while force feedback indicates the proper timing for in-hand rotation.
3D Diffusion Policy (DP3) is selected as our imitation learning algorithm, and we use Realsense L515 to acquire the point cloud inputs, which are then downsampled to 1024 points using farthest point sampling. The data collected by DOGlove is used to train policies for various downstream tasks. We evaluate imitation learning performance on 2 contact-rich tasks.
Press and Move Box: During data collection, the box is randomly placed within a 30×20 cm area,
and DOGlove collects 40 demonstrations to train the policy.
In evaluation, the box is also randomly placed in the same area.
Across 20 trials, the success rate is 85% (17/20).
Pick and Place Teddy Bear: During data collection, the teddy bear’s initial position is randomized within a 30×20 cm area,
and DOGlove collects 40 demonstrations to train the policy.
In evaluation, the bear is again randomly placed in the same area.
Across 20 trials, the success rate is 70% (14/20).
@INPROCEEDINGS{ZhangH-RSS-25,
AUTHOR = {Han Zhang AND Songbo Hu AND Zhecheng Yuan AND Huazhe Xu},
TITLE = {{DOGlove: Dexterous Manipulation with a Low-Cost Open-Source Haptic Force Feedback Glove}},
BOOKTITLE = {Proceedings of Robotics: Science and Systems},
YEAR = {2025},
ADDRESS = {LosAngeles, CA, USA},
MONTH = {June},
DOI = {10.15607/RSS.2025.XXI.104}
}If you have any questions, please feel free to contact Han Zhang.
We would like to thank Zhengrong Xue, Gu Zhang, Changyi Lin, Mengda Xu, and Yifan Hou for their invaluable advice and fruitful discussions on hardware design and learning policies. We also appreciate Wenhao Ding and Laixi Shi for their insightful discussions and feedback. Additionally, we thank Yichuan Gao, Xiaoyan Yang, Xinyao Qin, and Botian Xu for their assistance with the user study. Special thanks to Skyentific, Gennady Plyushchev, for their innovative contributions to the unconventional cable-driven joint design. We are also grateful to Tiansheng Sun and Guanghan Pan for their open-source repository of the HTC Vive Tracker Python API. We extend our appreciation to Yitong Wang for her help in creating elegant graphic renderings of the hardware design. Tsinghua University Dushi Program supports this project.